




Amazon S3 is one of the most widely used services in the AWS ecosystem. In this article, we are going to talk about some advanced Amazon S3 concepts and features. This article is a sequel to an article I wrote on the basics of Amazon S3, so if you are new to S3 or haven't read that article yet, click here to give it a read. Reading it will help you to better understand this one just as watching season one of a television series helps you understand season two better. To give you an overview of what is to come, here are some of the concepts and features we are going to explore: S3 Lifecycle Policies, S3 Requester Pays, S3 Encryption, S3 Access Control and more. Now let's take a look at each of these concepts to help us better understand the power of Amazon S3.
S3 Lifecycle Rules
Amazon S3 allows its users the freedom of transitioning objects stored in S3 buckets between different storage classes based on the usage or access pattern of these objects. Moving objects between storage classes helps in optimizing storage costs and you can transition objects manually but for more operational efficiency, Lifecycle Rules are used to transition S3 objects between storage classes automatically based on transition rules or policies you define. Before going on to talk more about Lifecycle rules, S3 uses a waterfall model to transition objects between different storage classes. See the image below to understand this model.
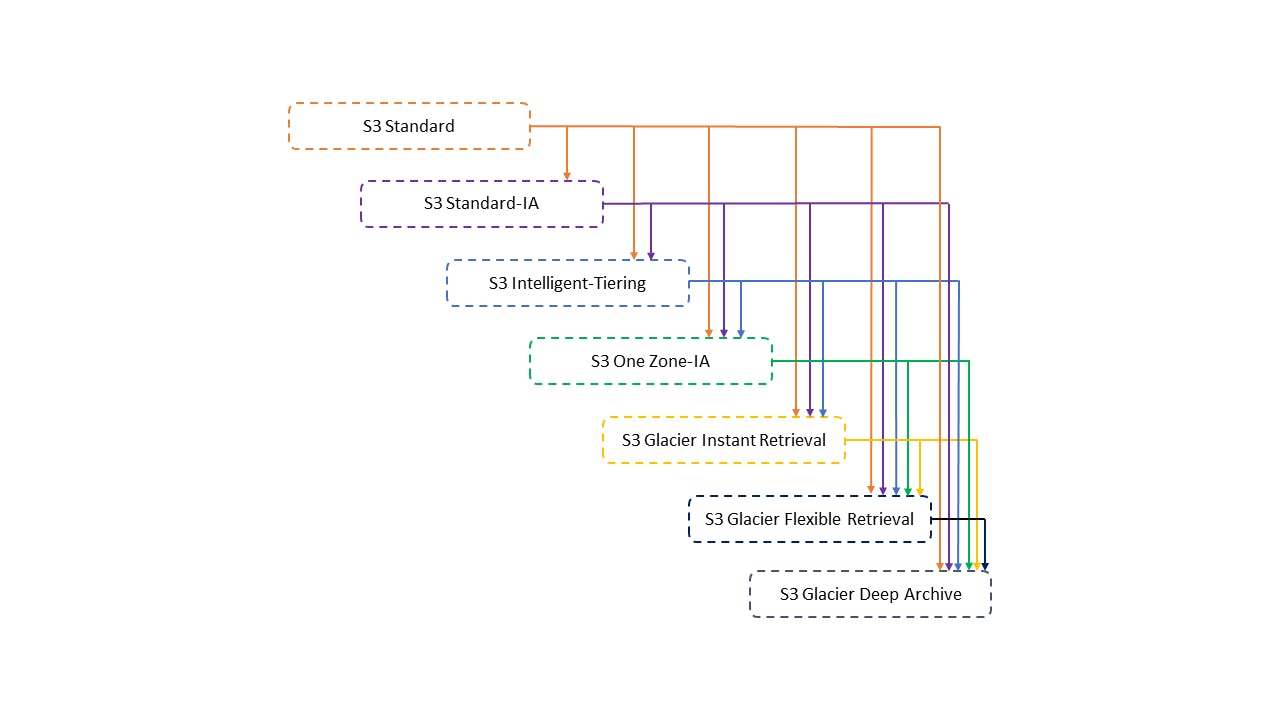
With Lifecycle rules, you can create transition actions that automatically move objects between storage classes. For example, you can create a transition action that moves objects from S3 Standard to S3 Standard-IA 60 days after they are uploaded into your S3 buckets. Lifecycle rules also allow you to set expiration actions which is basically configuring objects to expire or be deleted after a specified number of days. For example, you can set an expiration action for files such as access log files to be deleted after say six months or you can use expiration actions to delete older versions of objects if you have enabled versioning. These expiration actions allow you to automatically delete objects that are no longer needed thereby helping you minimize storage costs.
To put things into perspective, let's see a real-world example of Lifecycle rules being used. A media streaming company uses Amazon S3 to store its video content. To optimize storage costs, they define S3 lifecycle rules to automatically transition older video files from the frequently accessed S3 Standard storage class to the more cost-effective S3 Glacier Deep Archive storage class after a year. This helps them ensure long-term retention while minimizing storage costs.
S3 Requester Pays
By default, an S3 bucket owner pays for all the S3 storage and data transfer costs accrued by their bucket. With the Requester Pays feature, you configure buckets so that the person requesting data stored in an S3 bucket pays for the associated cost, rather than putting the cost on the bucket owner. When a bucket has the Requester Pays feature enabled, anyone accessing the objects in that bucket is responsible for covering the associated costs. This can be useful in scenarios where you want to share data with others but don't want to incur the costs yourself. It provides a way to share the cost burden with the users accessing the data in the bucket.
S3 Event Notifications
S3 Events refer to the actions being performed within or on your S3 bucket. Events can be actions such as uploading an object, restoring an object, removing an object or enabling replication. S3 Event Notifications is an S3 feature that allows you to set up notifications for specific events (actions) that occur in your S3 bucket. When enabled, S3 can automatically send notifications to various AWS services, such as Lambda functions, SQS queues, SNS topics, or Kinesis Data Streams, when certain events happen. With S3 Event Notifications, you can automate workflows and trigger actions in response to changes in your S3 bucket. For instance, you can configure a Lambda function to be invoked whenever a new object is uploaded to your bucket, allowing you to perform custom processing or integration with other services.
A real-life scenario for using S3 Event Notifications is when you have an application that allows users to upload images. By configuring an S3 Event Notification on the source bucket, you can automatically trigger an AWS Lambda function whenever a new image is uploaded. The Lambda function can generate thumbnail images and store them in a separate bucket. This automation ensures that thumbnails are created for each uploaded image, improving user experience and enabling you to maintain an auditable record of the original images and their thumbnails.
S3 Multi-part Uploads and Transfer Acceleration
Multi-part uploads and S3 Transfer Acceleration are S3 features that help boost performance when you are transferring data into S3 buckets. Multi-part uploads allow you to upload large objects in parts, which improves the efficiency and reliability of the upload process. With multi-part uploads, you can break a large file into smaller parts and upload them concurrently. This helps overcome limitations like network disruptions or slow connections, as you can resume the upload of individual parts without starting over. It is recommended that you use this feature for objects that exceed 100MB. However, multi-part upload MUST be used for files greater than 5GB. Multi-part upload uses parallelization, where a file is split into different multiple parts and the parts are uploaded simultaneously, resulting in faster upload times. Once all the parts are uploaded, S3 assembles them back into a single object. This feature is particularly useful for large files, such as videos, backups, or datasets, where uploading the entire file in one go may be impractical or prone to failure.
S3 Transfer Acceleration is a feature that helps increase data transfer speeds for uploads and downloads to and from S3 buckets by leveraging Amazon CloudFront's global network of edge locations. With S3 Transfer Acceleration, you can achieve faster data transfers, especially for larger objects and over long distances. It works by routing the data through the nearest CloudFront edge location, which is geographically closer to the client or the S3 bucket. This reduces the latency associated with transferring data over long distances. To use S3 Transfer Acceleration, you simply need to enable it for your S3 bucket. Once enabled, you can use the accelerated endpoint for your S3 bucket instead of the standard S3 endpoint.
S3 Object Lambda
It is a data customization feature that allows you to add custom code to S3 GET requests to modify and transform objects on the fly without having to make a copy of the object or change the original data in the bucket. Object Lambda works by intercepting GET requests for an S3 object and routing them to an AWS lambda function that processes the object's data and returns a modified version of the object to the requester. To use this feature, you can create an S3 Object Lambda Access Point which is a unique endpoint that provides access to the Lambda function.
Now it's time for us to talk about advanced S3 features and concepts centred around security. These features include; S3 Encryption, S3 MFA Delete, S3 CORS, S3 Object Lock, and more.
S3 Encryption
To ensure the security of your data, S3 encrypts data when it is in transit as well as when it is at rest. Amazon S3 offers two mechanisms for object encryption. These encryption mechanisms are; Server-side Encryption (SSE) and Client-side Encryption (CSE). The SSE mechanism is subdivided into three other mechanisms depending on how encryption keys are managed. Let's look at each of these encryption mechanisms in small detail below.
Server-side Encryption with Amazon S3-Managed Keys (SSE-S3) — When you use this encryption mechanism, objects are encrypted and decrypted using encryption keys handled, managed and owned by AWS. When SSE-S3 is enabled for a bucket, Amazon S3 automatically encrypts each object uploaded to the bucket using AES-256 (Advanced Encryption Standard 256-bit) encryption. SSE-S3 is the default encryption mechanism in S3 and it is only used for the encryption of data that is at rest.
Server-side Encryption with KMS Keys stored in AWS KMS (SSE-KMS) — With SSE-KMS, objects are encrypted using keys managed by AWS Key Management Service (KMS). SSE-KMS provides an extra layer of security for your S3 objects by encrypting them with a customer master key (CMK) stored in AWS KMS. When you use SSE-KMS, S3 automatically encrypts your data at rest with a unique data key. This data key is then encrypted using your chosen CMK in AWS KMS. The encrypted data key is stored alongside the encrypted object in S3. This two-tiered encryption approach ensures that your data remains protected even if it is accessed or compromised. SSE-KMS provides additional security controls such as auditing, key rotation and access policies. It can be used to encrypt data at rest and data in transit.
Server-side Encryption with Customer-Provided Keys (SSE-C) — In SSE-C, encryption keys are managed by the customer and provided to S3 for object encryption. S3 does not store the encryption keys but it provides complete control over the complete encryption process and requires the customer to manage the keys and ensure their security.
Client-side Encryption (CSE) — In CSE, data is encrypted before it is uploaded to S3. This encryption option gives complete control of the encryption process to the customer. CSE is typically used by customers who have strict security requirements or customers who want to use their own encryption algorithm.
Amazon S3 uses Encryption in Transit to ensure that data is securely transmitted over the network between a client application and the S3 service. It helps protect data from unauthorized access or interception during transit. By default, Amazon S3 supports SSL/TLS encryption (encryption in flight) for all data transferred between a client and S3. When using HTTPS, data is encrypted using industry-standard SSL/TLS protocols thereby providing a secure communication channel. It is recommended that you use the HTTPS protocol when transferring data from a client to the S3 service. However, you MUST use HTTPS if you use the SSE-C encryption mechanism. To force encryption in transit (enforce the use of secure connections (HTTPS) when accessing your S3 resources) you can create a bucket policy that denies any action on your S3 bucket if the aws:SecureTransport condition evaluates to false. Refer to the bucket policy below to better understand what this means.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ForceSSL",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:*",
"Resource": "arn:aws:s3:::your-bucket-name/*",
"Condition": {
"Bool": {
"aws:SecureTransport": "false"
}
}
}
]
}
With the policy above attached to an S3 bucket, any request made using HTTP will be denied, and only requests made using HTTPS will be allowed. By forcing encryption in transit, you ensure that all data transferred between your client application and Amazon S3 is encrypted using SSL/TLS protocols, protecting it from unauthorized access or interception during transit. This helps maintain the confidentiality and integrity of your data, reducing the risk of data breaches or tampering.
S3 Cross-Origin Resource Sharing(CORS)
Before going forward to look at S3 CORS, let's try to understand what CORS means. It is a mechanism that allows web browsers to make requests to a different domain than the one the web page originated from while enforcing security restrictions. By default, web browsers enforce a security policy known as the "same-origin policy" which prevents web pages from making requests to different domains. However, there are situations where you might want to fetch resources from a different domain, such as loading data from an API hosted on a different server. CORS enables this cross-origin communication by adding specific HTTP headers to the server's response. These headers inform the browser that the server allows requests from a different origin. The browser checks these headers and allows or denies the request based on the server's instructions. CORS helps protect user data and prevent malicious activities by enforcing restrictions on which domains can access resources. It ensures that only trusted origins are permitted to make cross-origin requests. Now onto S3 CORS.
When you enable CORS on your S3 bucket, you're telling the browser that it is allowed to make requests to your bucket from other domains thereby overwriting the same-origin policy. To configure CORS on your S3 bucket, you need to create a CORS configuration, which is a set of rules that define which domains can access your bucket and what types of requests they can make. These rules include things like allowed origins (domains), allowed HTTP methods (GET, PUT, DELETE etc.), and allowed headers. For instance, let's say you have a website hosted on the domain www.example.com and you want to allow requests from api.example.com to access resources in your S3 bucket. You can create a CORS configuration that specifies api.example.com as an allowed origin and allows certain HTTP methods like GET and POST. By enabling CORS on your S3 bucket and configuring the necessary rules, you ensure that your S3 resources are accessible to authorized domains while maintaining security and preventing unauthorized access.
S3 MFA Delete
It is a feature that requires users to use multi-factor authentification before carrying out operations such as permanently deleting an object version or suspending versioning on an S3 bucket. With S3 MFA Delete, a user needs to provide a one-time code generated by an authentication application (e.g. Google Authenticator) or an MFA hardware device before they can carry out operations like the ones listed above. To use MFA Delete on an S3 bucket, versioning must be enabled on the bucket and only the bucket owner can enable or disable MFA Delete.
S3 Access Logs
For audit purposes, you may want to log all access to an S3 bucket. This means any request made to an S3 bucket from any account, allowed or denied is logged to another S3 bucket. This log data can then be analyzed by data analytics tools such as Amazon Athena. For S3 logging to work, the target bucket(bucket in which logs are stored) must be in the same region as the bucket from where the logs are originating. When you enable access logging on an S3 bucket, Amazon S3 starts capturing detailed information about each request made to that bucket. This information includes the requester's IP address, the time of the request, the HTTP method used (such as GET or PUT), the response status, and more.
Warning: Never store log data in the same S3 bucket they were generated from to avoid creating a logging loop. When a logging loop occurs, each log entry generated by the bucket is written to the access logs, which triggers the creation of new log entries, and the process repeats indefinitely. This can result in an excessive amount of log data being generated, causing increased storage costs, potential performance issues, and difficulties in analyzing the logs effectively. SO DO NOT TRY THIS AT HOME!!
S3 Pre-signed URLs
This is an S3 feature that allows S3 users to generate URLs to grant temporary access to S3 resources. These URLs can be generated using the S3 console, AWS CLI or SDK. URLs generated via the S3 console can be active for a period ranging from 1 minute to 720 minutes (12 hours) before they expire while URLs generated using the AWS CLI can be active for up to 168 hours before they expire. Anyone using a pre-signed URL inherits the permissions of the IAM user or IAM role that generated the URL. Pre-signed URLs provide a secure way to grant temporary access to S3 objects without requiring recipients to have AWS credentials. Below is a sample use case for pre-signed URLs.
Use case: In an e-commerce website, S3 pre-signed URLs are used to securely share downloadable files with customers. When a user purchases a file, a time-limited URL is generated, allowing them to download the file securely. This ensures that only authorized users can access the files within a limited time frame.
S3 Glacier Vault Lock & S3 Object Lock
S3 Glacier Vault Lock is a feature that allows users to enforce compliance controls over their archived data in Glacier. It adopts a WORM (Write Once Read Many) model for data meaning that data stored in Glacier Vault Lock cannot be modified or deleted within a predefined period. Some use cases for Glacier Vault Lock are as follows;
A company may need to place a legal hold on data for ongoing litigations or
investigations. To ensure that the data is not tampered with during the litigation or investigation period, that data can be placed in Glacier Vault Lock.
It can also be used when an organization wants to archive its data for long periods while also preventing it from accidental deletion or tampering.
S3 Object Lock is a feature that provides an additional layer of security to objects in an S3 bucket. S3 Object Lock also adopts the WORM (Write Once Read Many) model for data. Once an object is locked using S3 Object Lock, it becomes immutable and cannot be modified or deleted for a specified retention period. This helps ensure data integrity and compliance with regulatory requirements. To use Object Lock on S3 objects, versioning must be enabled on the S3 bucket in which the objects are stored. In Object Lock, there are two retention modes namely; Compliance Retention Mode and Governance Retention Mode
Compliance Retention Mode — It enables you to enforce strict data retention policies for regulatory compliance purposes. In this retention mode, object versions cannot be deleted or overwritten by any user including the root user, the object retention mode cannot be changed, and the retention period cannot be shortened.
Governance Retention Mode — In this retention mode, most users cannot overwrite or delete an object version or alter its lock setting. However, some users have special permissions to change retention periods or delete objects.
S3 Access Points
S3 Access Points is a feature that provides a way to manage access to your S3 buckets at scale. Access Points provide a way to create unique hostnames to access specific buckets and their objects. They can be used to enforce separate access policies and compliance requirements for different applications, teams and regions. Access Points simplify security management for S3 buckets. With S3 Access Points, you can create unique access points for your buckets and define specific permissions and configurations for each access point. This allows you to grant granular access to different applications, teams, or users without compromising the security or performance of your entire bucket. Here's a real-world scenario where S3 Access Points can be used:
In a large organization with multiple departments, S3 Access Points provide a way to create separate access controls for different teams or applications. For example, you can have dedicated access points for Finance, Analytics, Customer Service, and Marketing. Each access point has its own policies, allowing fine-grained control over who can access specific data. This helps maintain data security, compliance, and isolation while using a centralized S3 bucket.
Final Thoughts
In this article, we have taken time to learn about advanced S3 features and paid special attention to the S3 features that are centred around security. The knowledge and insights gained from this article will help you build more resilient, cost-effective and performant solutions using Amazon S3. As always, thank you for reading and if you have any questions relating to the S3 service, I will be waiting to attend to them in the comment section.