
Building Resilient Architectures: Elastic Load Balancing and Auto Scaling for Continuous Availability & Performance in AWS


Designing resilient and highly performant infrastructures makes up some of the core pillars of building well-architected solutions on AWS. A resilient solution has high availability and is highly fault tolerant. Availability fundamentally refers to the ability of a system or resource to be accessible and functional when needed. Availability in AWS is expressed as the percentage of uptime in a given year. In this article, we are going to focus our attention on load balancing and auto-scaling, some of the ways AWS improves performance and ensures the availability of its services.
Auto Scaling
In AWS, auto-scaling refers to the ability to dynamically adjust computing resources in response to changes in demand, workload or traffic. It helps you optimize the performance of your applications while lowering infrastructure costs by easily and safely scaling resources. Scaling can be done in one of two ways which are; horizontally and vertically.
Horizontal Scaling means adding more resources to a group of resources to distribute workload and handle increased traffic. For example, you can add more EC2 instances to a group of instances to handle increased traffic during peak periods. With Horizontal Scaling, you can either scale in (remove) or scale out (add) your resources.
Vertical Scaling — In this scaling mode, more capacity is added to an already existing resource to handle increased workloads or traffic. An example of vertical scaling is when you upgrade an EC2 instance to a larger instance type with more CPU and memory to enable you to handle increased traffic or workload. With Vertical Scaling, you can either scale up (increase capacity) or scale down (decrease capacity).
AWS provides its customers with multiple options for scaling resources. Let's look at these options down below.
Amazon EC2 Auto Scaling
Amazon EC2 Auto Scaling helps you ensure that you have the correct number of EC2 instances available to handle the load for your application. With EC2 Auto Scaling, you define scaling policies that determine when and how your EC2 instances should be added or removed. These policies can be based on various metrics such as CPU utilization, network traffic, or application response time. When the defined thresholds are met, EC2 Auto Scaling automatically adds or removes instances to match the desired capacity. EC2 Auto Scaling integrates with other AWS services like Elastic Load Balancing (ELB) (more about this below) and Amazon CloudWatch to ensure that your application scales seamlessly. By leveraging EC2 Auto Scaling, you can achieve greater availability, improve fault tolerance, and optimize costs by dynamically adjusting the number of EC2 instances based on demand or changing workload and traffic patterns.
Now let's look at the scaling policies you can use to scale your EC2 resources. These scaling policies define how an Auto Scaling Group (ASG) should scale based on metrics or event triggers that you define. The scaling policies are; Simple, Target Tracking, and Step Scaling Policies.
Simple Scaling Policy: With this type of scaling policy, the number of instances is adjusted in response to a particular metric. It works by setting one or more CloudWatch alarms that trigger the scaling policy when the metric set breaches a predefined threshold. When the alarm is triggered, instances are added or removed from an ASG according to the rules defined in the scaling policy. The instances added or removed can be a fixed number of instances or a percentage of the current capacity of the ASG.
Target Tracking Scaling Policy: This scaling policy allows you to set a target value for a specific metric such as CPU utilization, memory usage or network traffic and then it implements scaling by automatically adjusting the number of instances in an Auto Scaling group to keep the metric close to the target value, ensuring efficient resource utilization and optimal application performance.
Step Scaling Policy: This scaling policy allows you to define scaling rules based on specified step adjustments. It enables you to scale your resources in response to varying workload conditions. With the step scaling policy, you can define multiple thresholds and corresponding scaling actions. Each threshold represents a step that triggers a scaling action. For example, you can define a step scaling policy to increase the number of instances in an ASG by a count of two when CPU utilization exceeds a threshold of 80% and also increase the number of instances by a count of four when CPU utilization exceeds 85%.
AWS Auto Scaling
AWS Auto Scaling is a service provided by AWS that enables you to automatically scale your resources in response to changes in demand. It monitors your applications and automatically adjusts capacity to maintain steady, predictable performance at the lowest possible cost. AWS Auto Scaling makes it easy to set up application scaling for multiple resources across multiple services in minutes. The service provides a simple, powerful user interface that lets you build scaling plans for resources including EC2 instances and Spot Fleets, Amazon ECS tasks, Amazon DynamoDB tables and indexes, and Amazon Aurora Replicas. AWS Auto Scaling makes scaling simple with recommendations that allow you to optimize performance, costs, or balance between them. You should consider using AWS Auto Scaling if you have an application that uses one or more scalable resources and experiences variable load. A good example would be an e-commerce application that receives variable traffic throughout the day. It follows a standard three-tier architecture with Elastic Load Balancing for distributing incoming traffic, Amazon EC2 for the compute layer, and DynamoDB for the data layer. In this case, AWS Auto Scaling will scale one or more EC2 Auto Scaling groups and DynamoDB tables that are powering the application in response to changes in demand.
Elastic Load Balancing (ELB)
Elastic Load Balancing is a service provided by AWS that automatically distributes incoming application traffic across multiple target resources, such as Amazon EC2 instances, containers, and IP addresses in one or more Availability Zones. It monitors the health of its registered targets, and routes traffic only to the healthy targets. Elastic Load Balancing scales your load balancer capacity automatically in response to changes in incoming traffic. Using this service helps increase the availability and fault tolerance of your application. ELB supports the following types of load balancers: Application Load Balancers, Network Load Balancers, Gateway Load Balancers, and Classic Load Balancers. We are going to look at each of these load balancers briefly to enable you to choose the load balancer that best suits your specific needs.
Application Load Balancers make routing decisions at the application layer (layer 7) of the Open Systems Interconnection (OSI) model and they are designed to handle HTTP and HTTPS traffic. ALBs support various routing methods, including content-based routing, which allows you to route requests to different target groups based on the content of the request. They can route traffic based on hostnames, paths, query strings, or headers.
Network Load Balancers make routing decisions at the transport layer (layer 4) of the OSI model, allowing for highly scalable and efficient load balancing of TCP and UDP traffic. NLBs can handle millions of requests per second. NLBs are optimized for handling high volumes of traffic with low latency. They are ideal for applications that require fast response times, such as gaming or financial services. They support DSR (Direct Server Return), where the load balancer routes traffic to the backend and the response is sent directly back to the client, bypassing the load balancer. This can be advantageous for reducing latency and offloading processing from the load balancer.
Gateway Load Balancers operate at the Layer 3 of the OSI model, the network layer and they are designed to distribute traffic to multiple virtual appliances such as firewalls, intrusion detection systems and other security or networking appliances. They provide both Layer 3 gateway and Layer 4 load balancing capabilities. They are architected to handle millions of requests/second and volatile traffic patterns with extremely low latency.
Classic Load Balancers distribute incoming traffic across multiple EC2 instances and they operate at the transport layer (Layer 4) and can handle both TCP and SSL/TLS traffic. They automatically distribute traffic across healthy instances in response to incoming requests, helping to improve application availability and fault tolerance. It's important to note that Classic Load Balancer is a legacy service (is deprecated), and AWS recommends using Application Load Balancers or Network Load Balancers for new applications.
Now let us talk about some Elastic Load Balancing features and how they can help us build more performant solutions on AWS.
Sticky Sessions (Session Affinity)
It is a feature of ELBs that allows the load balancer to route subsequent requests from a client to the same backend server or instance that served the client's initial request. When session affinity is enabled on an ELB, the load balancer assigns a unique identifier, known as a session cookie, to each client's initial request. This session cookie contains information that identifies the specific backend server that handled the request. Subsequent requests from the same client are then routed to the same backend server based on the session cookie information. Requests from the client can only be routed to different backend servers when its assigned session cookie expires. This helps maintain session continuity and ensures that client-specific data or session state is preserved. This Session affinity feature is commonly used in applications that require session persistence, such as e-commerce platforms, web applications with user login sessions, or any scenario where maintaining user context or state is important. The load balancer types that support session stickiness are the Application Load Balancer and Classic Load Balancer. NLBs operate at the transport layer (Layer 4) and do not maintain session state. Therefore, if session stickiness is a requirement for your application, it is recommended that you use an ALB.
Cross-zone Load Balancing
It is a feature of Elastic Load Balancers that allows them to evenly distribute incoming traffic across all registered target resources in the same or different Availability Zones. When cross-zone load balancing is disabled, each load balancer node distributes traffic only across the registered target resources in its Availability Zone.
The following diagrams demonstrate the effect of cross-zone load balancing with round robin as the default routing algorithm. There are two enabled Availability Zones, with two targets in Availability Zone A and eight targets in Availability Zone B. Clients send requests, and Amazon Route 53 responds to each request with the IP address of one of the load balancer nodes. Based on the round robin routing algorithm, traffic is distributed such that each load balancer node receives 50% of the traffic from the clients. Each load balancer node distributes its share of the traffic across the registered targets in its scope.
If cross-zone load balancing is enabled, each of the 10 targets receives 10% of the traffic. This is because each load balancer node can route its 50% of the client traffic to all 10 targets.
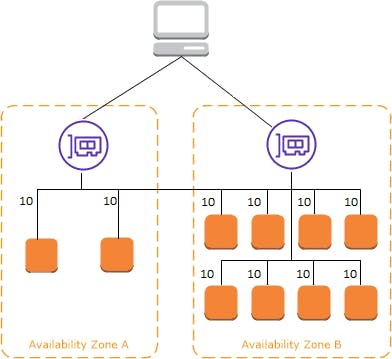
If cross-zone load balancing is disabled:
Each of the two targets in Availability Zone A receives 25% of the traffic.
Each of the eight targets in Availability Zone B receives 6.25% of the traffic.
This is because each load balancer node can route its 50% of the client traffic only to targets in its Availability Zone.
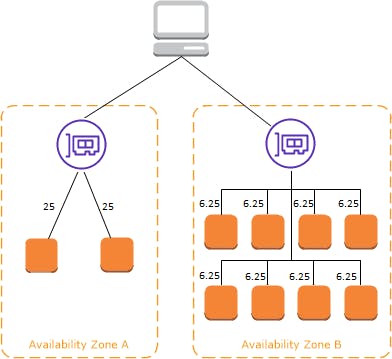
With Application Load Balancers, cross-zone load balancing is always enabled at the load balancer level. At the target group level, cross-zone load balancing can be disabled. With Network Load Balancers and Gateway Load Balancers, cross-zone load balancing is disabled by default. After you create the load balancer, you can enable or disable cross-zone load balancing at any time. When you create a Classic Load Balancer, the default for cross-zone load balancing depends on how you create the load balancer. With the API or CLI, cross-zone load balancing is disabled by default. With the AWS Management Console, the option to enable cross-zone load balancing is selected by default. After you create a Classic Load Balancer, you can enable or disable cross-zone load balancing at any time.
Connection Draining
Connection draining, also known as connection termination, is a load-balancing feature that allows load balancers to handle in-flight requests before gracefully terminating connections with backend instances. When enabled, connection draining ensures that active requests are completed and no new requests are sent to the instances undergoing deregistration or termination. The purpose of this feature is to prevent disruption to active requests and maintain a smooth user experience during instances' lifecycle changes, such as scaling down, health checks, or instance termination. It allows the load balancer to gradually stop sending new requests to the instances being removed from service. During the connection draining process, the load balancer stops sending new requests to the affected instances while allowing existing connections to complete within a specified timeout period. Once the timeout period elapses or all in-flight requests are completed, the load balancer terminates the remaining connections. Connection draining is particularly useful in scenarios where instances need to be taken out of service for maintenance, deployments, or when scaling down the number of instances. Allowing active requests to complete gracefully helps minimize the impact on ongoing user interactions and prevents potential data loss or interruption.
Final thoughts
Ensuring the continuous availability of your business solutions built on AWS is very crucial. Leveraging the power of Elastic Load Balancing and Auto Scaling helps businesses to achieve continuous availability for their applications. ELBs distribute incoming traffic across multiple instances, ensuring efficient load balancing and high availability. Combined with Auto Scaling, the infrastructure can dynamically scale in or out based on demand, adapting to fluctuating traffic patterns, maintaining optimal performance and ensuring operational efficiency. With these services, businesses can build robust and resilient architectures that provide seamless user experiences, increased fault tolerance, and improved scalability thereby meeting the needs of their users, while also benefiting from the flexibility and cost-effectiveness of cloud computing.